 In a famous article published 1951 ((Various techniques used in connection with random digits. NIST journal, Applied Math Series, 12:36-38, 1951. This article does not seem to be available online, though it is widely cited. It is reprinted in pages 768-770 of Von Neumann’s collected works, Vol. 5, Pergamon Press 1961)), John Von Neumann presented a way of skew-correcting a stream of random digits so as to ensure that 0s and 1s appeared with equal probability. This article introduces a simple and mentally workable generalization of his technique to random dice, so a loaded die can be used to uniformly draw numbers from the set \(\{1, 2, 3, 4, 5, 6\}\), with reasonable success.
In a famous article published 1951 ((Various techniques used in connection with random digits. NIST journal, Applied Math Series, 12:36-38, 1951. This article does not seem to be available online, though it is widely cited. It is reprinted in pages 768-770 of Von Neumann’s collected works, Vol. 5, Pergamon Press 1961)), John Von Neumann presented a way of skew-correcting a stream of random digits so as to ensure that 0s and 1s appeared with equal probability. This article introduces a simple and mentally workable generalization of his technique to random dice, so a loaded die can be used to uniformly draw numbers from the set \(\{1, 2, 3, 4, 5, 6\}\), with reasonable success.
Von Neumann skew-correction algorithm
Biased coins
Von Neumann’s originally proposes the following technique for getting an unbiased result from a biased coin :
If independence of successive tosses is assumed, we can reconstruct a 50-50 chance out of even a badly biased coin by tossing twice. If we get heads-heads or tails-tails, we reject the tosses and try again. If we get heads-tails (or tails-heads), we accept the result as heads (or tails).
This algorithm is illustrated below:
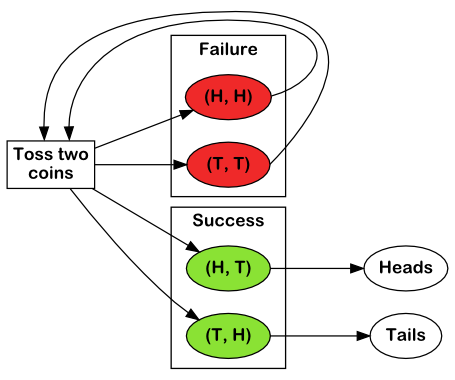
Flowchart recapitulating Von Neumann’s bias-suppressing algorithm
This amazingly simple strategy does yield heads and tails with equal probabilities, because coin tosses, though biased, are assumed to be independent. Therefore, if heads come out with probability \(p\), and tails with probability \(1-p\), then both (head, tails) and (tails, heads) sequences occur with probability \(p(1-p)\).
Removing the bias from a stream of random digits
Generalizing this technique to a stream of random digits is straightforward: pack digits two-by-to, discard any pair of two equal digits (00 or 11), and finally convert 01 to 0 and 10 to 1.
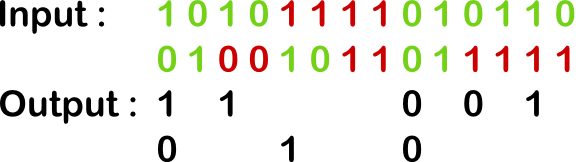
Illustration of Von Neumann’s biased-suppressing algorithm on a stream of random digits
Probabilistic remarks
Expected rejection rate
Continuing on previous calculations, since each coin toss is taken to be independent from the others, both (heads, tails) and (tails, heads) sequences will occur with probability \(p(1-p)\), while (heads, heads) and (tails, tails) sequences will occur with respective probabilities \(p^2\) and \((1-p)^2\).
Define the expected rejection rate \(r\) to be the the probability of obtaining (heads, heads) or (tails, tails) (and thus of discarding the sequence). Then \(r = p^2 + (1-p)^2 = 1 – 2 ⋅ p(1 – p) = (1/2) + 2 ⋅ (p – 1/2)^2\), which implies that \(r ≥ 1/2\). In other words, in the best case (when the coin is perfectly balanced), half of the coin sequences will be discarded.
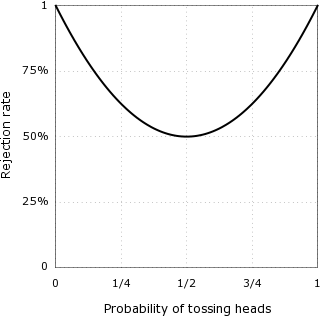
Rejection rate as a function of heads probability
Expected number of tosses
Since the rejection rate is \(r = 1 – 2 ⋅ p(1 – p)\), the odds of discarding exactly \(n\) two-coins sequences before obtaining an acceptable sequence are \(r^n ⋅ (1-r)\), and the expected number of two-coins sequences to be discarded is \(d = \sum_{k=0}^\infty k ⋅ r^k ⋅ (1-r) = \frac{r}{1-r}\).
Indeed, $$\sum_{k=0}^\infty k ⋅ r^k ⋅ (1-r) = r(1-r) ⋅ \sum_{k=0}^\infty k r^{k-1} = r(1-r) ⋅ \frac{∂}{∂r} \sum_{k=0}^\infty r^k = r(1-r) ⋅ \frac{∂}{∂r} \frac{1}{1-r} = \frac{r}{1-r}$$
Now, if \(d\) two-coins sequences are discarded before an acceptable sequence is obtained, then the number of coin tosses required is \(2 ⋅ (1 + d) = \frac{1}{p(1-p)} ≥ 4\). In other words, it will take in the best case an average of 4 single-coin tosses to obtain an acceptable sequence. Or, as Von Neumann puts it,
The resulting process is rigorously unbiased, although the amended process is at most 25 percent as efficient as ordinary coin-tossing.
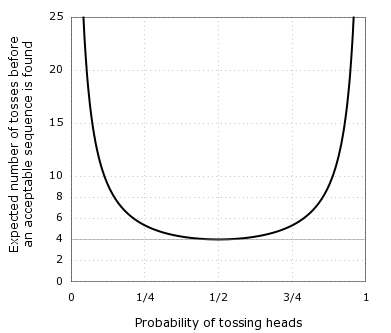
Expected number of tosses before an acceptable two-coins sequence is found, plotted as a function of heads probability
A generalization to loaded dice
The general idea behind Von-Neumann style skew-correction techniques is to consider sequences of coin tosses instead of isolate ones, and pick a sequence length long enough that an even number of possible outcomes have equal probabilities. These outcomes can then be split in two groups, one representing heads and the other representing tails, while other outcomes are discarded.
Generalizing this strategy to weighted dice excludes picking a sequence length \(n ≤ 2\), since no subset of possible outcomes of equal probability for \(n=1\) or \(n = 2\) has a cardinal divisible by six. For \(n=3\), on the other hand, the outcomes of any dice (crooked or not) can be partitioned into six categories of equal probability according to the relative ordering of the successive numbers rolled, provided these numbers are all different — that is, sequences can be grouped according to whether the second number is greater (↑) or smaller (↓) than the first, and whether the third number is greater (↑↑↑, ↓↑↑) or smaller (↑↓↓, ↓↓↓) than both the first and the second, or between them (↑↑↓, ↓↓↑).
This strategy is illustrated in the diagram below, which provides a reference table for interpreting sequences of three rolls of a loaded dice to produce unbiased results. Should the same number occur twice, all three rolls should be discarded, and the process should be started over.
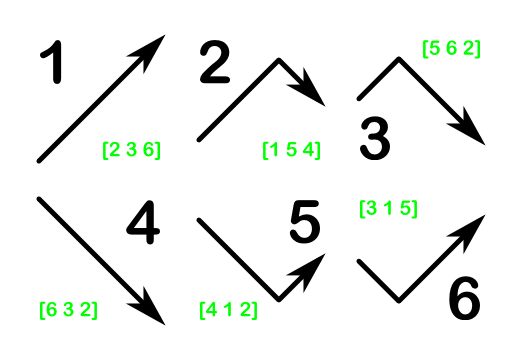
Decision table for suppressing dice bias. Given a sequence of three throws, chart the three throws so as to form an arrow pattern, and use this table to obtain the corresponding result. Examples are given in green for each pattern. Using this table, rolling \(1 2 5\) would yield a \(1\), while \(1 5 2\) would yield a \(2\), and \(5 2 1\), a \(4\).
All six possible orderings will occur with equal probability, because each of the sequences belonging to any of these orderings matches exactly one sequence of equal probability in every other ordering: for example, \(1 2 4\) matches the ordering ↑↑↑, whereas \(2 1 4\), which is equally likely, matches ↓↑↑.
Implementation
Given a sequence of three independent rolls of a possibly biased die, this function returns a fair dice roll using the previously exposed technique:
def translate(*rolls): # returns False if 'rolls' contains duplicates, and a fair dice roll otherwise # Possible relative ordering of the three rolls. 1 2 3 is ↑↑↑, 2 1 3 is ↓↑↑. deltas = [(True, True, True), (True, True, False), (True, False, False), (False, False, False), (False, False, True), (False, True, True)] # True stands for ↑ (r1, r2, r3) = rolls; unique = len(set(rolls)) >= 3 return unique and 1 + sequences.index((r2 > r1, r3 > r1, r3 > r2))
Here’s a test function. The bias parameters measures how unbalanced the die is: the higher the bias, the higher the probability to roll a 6.
def unfair_roll(bias):
return random.choice([1, 2, 3, 4, 5] + [6]*bias)
def test(number_of_rolls, bias):
count = [0]*7
bias = max(bias, 1)
for roll_id in range(0, number_of_rolls):
rolls = unfair_roll(bias), unfair_roll(bias), unfair_roll(bias)
count[translate(*rolls) or 0] += 1
print("Rejection rate: {:.2f}%".format(count[0] / number_of_rolls * 100))
print("Relative digit frequency:")
for digit in range(1, 6 + 1):
print(" {}: {:.2f}%".format(digit, count[digit] / number_of_rolls * 100))
print("Before correction, 6 was {} times more likely to occur"
" than other digits.".format(bias))
Here’s a single run for 50 000 sequences of three rolls of a die ten times more likely to give a 6:
>>> test(50*1000, 10) Rejection rate: 80.52% Relative digit frequency: 1: 3.24% 2: 3.30% 3: 3.26% 4: 3.18% 5: 3.17% 6: 3.32% Before correction, 6 was 10 times more likely to occur than other digits.
Conclusion and further remarks
Though easy to work out mentally, this bias-correction technique for dice is far from optimal. Indeed, the minimal rejection rate (obtained for a perfectly balanced dice) is about 44%, and the rejection rate quickly increases as the bias gets stronger, reaching 64% when 6 is 5 times more likely to occur than other individual digits.
More subtle techniques, which I will discuss in a future article, take the rejection rate down to 1.5% for perfectly balanced dice, and keep it under 7% for dice with a 6 to 1 chance of getting a 6 over any other digit.
Do you know other strategies to even the odds when playing with a loaded dice? Sound off in the comments!
Wonderful. I’ve been looking for something like this in order to extract randomness from text. Now, it would be more useful if we could start from a set of 5 (polybius square), 9, 10 (straddling checkerboard) or 26 (straight text) rather than 6. How would you go about that?
Pingback: Chaos from Order - PR Gomez
Pingback: Chaos from order – PR Gomez
” which I will discuss in a future article, take the rejection rate down to 1.5% for perfectly balanced dice”
So I eagerly went to the home page to find this future article……only to discover that the blog ceased after only a few more articles. Bummer.
Pingback: Do imperfections in dice make them unsuitable to make really good bitcoin private keys? - Finance Money