.png) Comparing strings is often — erroneously — said to be a costly process. In this article I derive the theoretical asymptotic cost of comparing random strings of arbitrary length, and measure it in C, C++, C# and Python.
Comparing strings is often — erroneously — said to be a costly process. In this article I derive the theoretical asymptotic cost of comparing random strings of arbitrary length, and measure it in C, C++, C# and Python.
Theoretical amortized cost
Infinite strings
Suppose one draws two random strings \(A = “a_0a_1a_2…”\) and \(B = “b_0b_1b_2…”\) of infinite length, with \(a_n\) and \(b_n\) respectively denoting the \(n\)th character of \(A\) and \(B\). We will assume that characters are independent, and uniformly drawn over the set \(\{a, b, c, …, z\}\). For now, we will consider all strings to be of infinite length — we’ll study bounded-length strings in the next section.
Given that characters making up \(A\) and \(B\) are independent, the probability of \(A\) differing from \(B\) at index \(n\) is \(25/26\). Conversely, the probability of \(A\) matching string \(B\) at index \(n\) is \(1/26\).
Consequently, the probability of \(A\) matching \(B\) up to index \(n – 1\), and differing at index \(n\), is \((1/26)^n ⋅ (25/26)\). Therefore, given that comparing strings up to index \(n\) included is \((n+1)\) the expected number of characters to compare to discriminate \(A\) and \(B\) is $$ C = \sum_{n=0}^{\infty} (n+1) ⋅ (1/26)^n ⋅ (25/26) = 26/25$$
Indeed, defining \(C(x) = (1-x) ⋅ \sum_{n=0}^{\infty} (n+1) x^n\), the expected number of comparisons \(C\) required to discriminate \(A\) and \(B\) is \(C(1/26)\). Now \(C(x) = (1-x) ⋅ \sum_{n=0}^{\infty} \frac{∂ x^n}{∂ x} = (1-x) ⋅ \frac{∂ \sum_{n=0}^{\infty} x^{n+1}}{∂ x} = (1-x) ⋅ (1-x)^{-2} = 1/(1-x)\). Plugging \(x=1/26\) yields \(C = 26/25 \approx 1.04\).
In other words, it takes an average of \(1.04\) character comparisons to discriminate two random strings of infinite length. That’s rather cheap.
Finite strings
In this section we assume that \(A\) and \(B\) are bounded in length by a constant \(L\). This implies that the probability of the comparison routine reaching any index greater than \((L-1)\) is \(0\); hence the expected number of comparisons \(C_L\) is $$C_L = \sum_{n=0}^{L-1} (n+1) ⋅ (1/26)^n ⋅ (25/26) = (26/25) ⋅ (1 – \frac{25L + 26}{26^{L+1}})$$
For any \(L > 3\), this is virtually indistinguishable from the previously calculated value \(C = 1.04\).
Conclusion
The theoretical amortized time required to compare two strings is constant — independent of their length. Of course, there may be a sizeable overhead associated to comparing strings instead of ints: experimental measurements of this overhead are presented below.
Experimental measurements
The following charts present the time it took to perform 100’000 string comparisons on my laptop, compared to a baseline of 100’000 integer comparisons, in 3 different programming languages and for string lengths varying from 1 to 500 characters. Despite large variations for small string lengths, measured times quickly converge to a fixed limit as strings lengthen ((If you want to experiment with the tests, you can download the full python, C++, or C# source code.)).
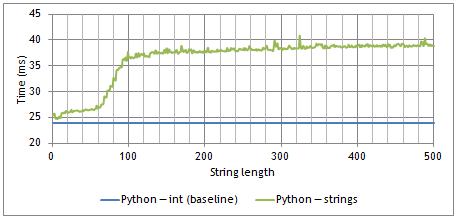
Time required to compare 100’000 pairs of random strings, as a function of string length, in Python (3.2.3)
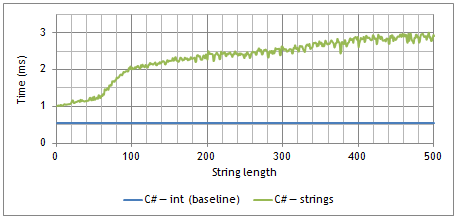
Time required to compare 100’000 pairs of random strings, as a function of string length, in C# (csc 4.0.30319.17929)
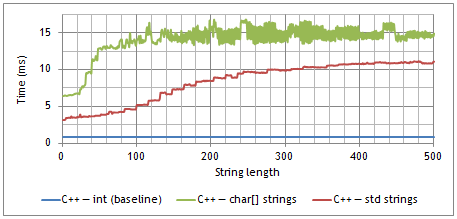
Time required to compare 100’000 pairs of random strings, as a function of string length, in C++ (gcc 4.3.4).
Remarks
Though large strings (over ~200 characters) experimentally match our statistical model, small strings exhibit a much more complex behaviour. I can think of a two causes for such variations:
- String interning: Python interns some strings — exactly which depends on the implementation. On my laptop, this turns small (< 64 characters) string comparisons into direct pointer comparisons, which are about as fast as integer comparisons.
- Locality: In C++ in particular, under certain conditions, applying a function to a char* gets slower as the referred string lengthens, even if the function only access the first few elements. The effect is barely noticeable for strings over 200 characters.
Conclusion
Comparing strings, especially small strings, is very fast. The amortized time required to compare two strings is bounded by a constant, which is experimentally about twice the time required to compare two integers in high level languages like Python or C#, and 5 to 7 times higher in low-levels languages like C++.
Do you usually try to avoid comparing strings? Do you have a more detailed explanation of the irregularities observed for lengths < 200 characters? Tell us comments!
Real life strings (and, in general, performance) can be surprisingly different from predictions. I have come across several situations where strings being compared are not random, but (for example) are written by a human, and tend to have common prefixes. Consider a linker: mangled C++ names are often identical until the end of the symbol name, so to resolve a reference could require far more of the string to be compared. In this situation I have used different data structures to quickly locate symbols.
The best approach is probably to write the simplest code you think you can get away with, release it, and measure how it performs in real life. Try to collect at least coarse-grained measurement data from your installed software in the field, so that you can pinpoint your users’ hotspots. I’ve used this approach before, and you’re right: many times using straight string comparisons is just fine! But a few hotspots get replaced with better implementations.
Hi Neil, and thanks for your comment !
You’re right, when dealing with non-random strings collisions on the first few characters may happen much more often than in the ideal, random strings case. A strategy that’s sometimes used to mitigate this problem is to restore an appearance of randomness by storing a hash with each string (calculated when building the string, so if the hash has a linear complexity it doesn’t add much to the cost of building the string), and comparing hashes before comparing the underlying strings.
Also, thanks for the linker example: I hadn’t thought of it at all, but it’s indeed a good example where partial collisions are very likely.
Surprised that comparing c++ STL strings were 5x? slower than c# string comparisons. Can’t imagine why that would be the case.
Hi Mark, thanks for your comment!
This might be linked to my compilation settings, although I’ve tried to disable all optimizations in both cases. Interestingly, the C# implementation uses generics to compare both arrays, while the C++ version doesn’t use templates (they were removed because I couldn’t use them to compare C-style char[] strings).
These performance variations are partly why I put each language on a separate graph: I’m not sure such a small benchmark can be used to compare languages.
Your proof using power series is great, but you forgot to justify swapping between the infinite sum and the derivative operator.
Indeed. The simplest (though somewhat pedestrian) way to justify that calculation is probably to write out the explicit truncated power series, namely [latex]C_L(x) = (1-x)\sum_{n<L}\frac{∂ x^{n+1}}{∂ x} = (1-x)\frac{∂ \sum_{n<L} x^{n+1}}{∂ x} = (1-x)^{-1}(1 – (L+1)x^L – Lx^{L+1})[/latex], which converges to [latex]1/(1-x)[/latex] as [latex]L \to \infty[/latex]. 12.40.22 pour plus de détails ;)
A simple solution to deal with strings with some kind of fixed prefix is to compare them in reverse.
Indeed! That’s a good way to avoid the cost of the prefix comparison. Going one step further, if one is concerned that an attacker could take advantage of a comparison slowdown by maliciously crafting strings, then one can choose a random permutation and compare the strings character by character, in the order that the permutation induces. Bonus point if the permutation is local enough that it doesn’t yield terrible cache behavior (i.e. if consecutive indices are not sent further apart than the size of one cache line by the permutation).
Thanks for posting this interesting blog. I was wondering what about calculating the similarity of two strings instead of merely compare two strings (and get an answer of True or False). Do you think C# or C++ will be faster than Python in that case as well?
If there are any C# programmers here who want to see how various methods stack up against other comparison methods, check out this blog post which benchmarks half a dozen ways:
http://cc.davelozinski.com/c-sharp/fastest-way-to-compare-strings
I like the “thinking outside the box” methods they tried like using HashSet keys (even though it isn’t practical in every day code).